


"I think you're testing me": Claude 3 LLM called out creators while they tested its limits
Anthropic's new LLM told prompters it knew they were testing it

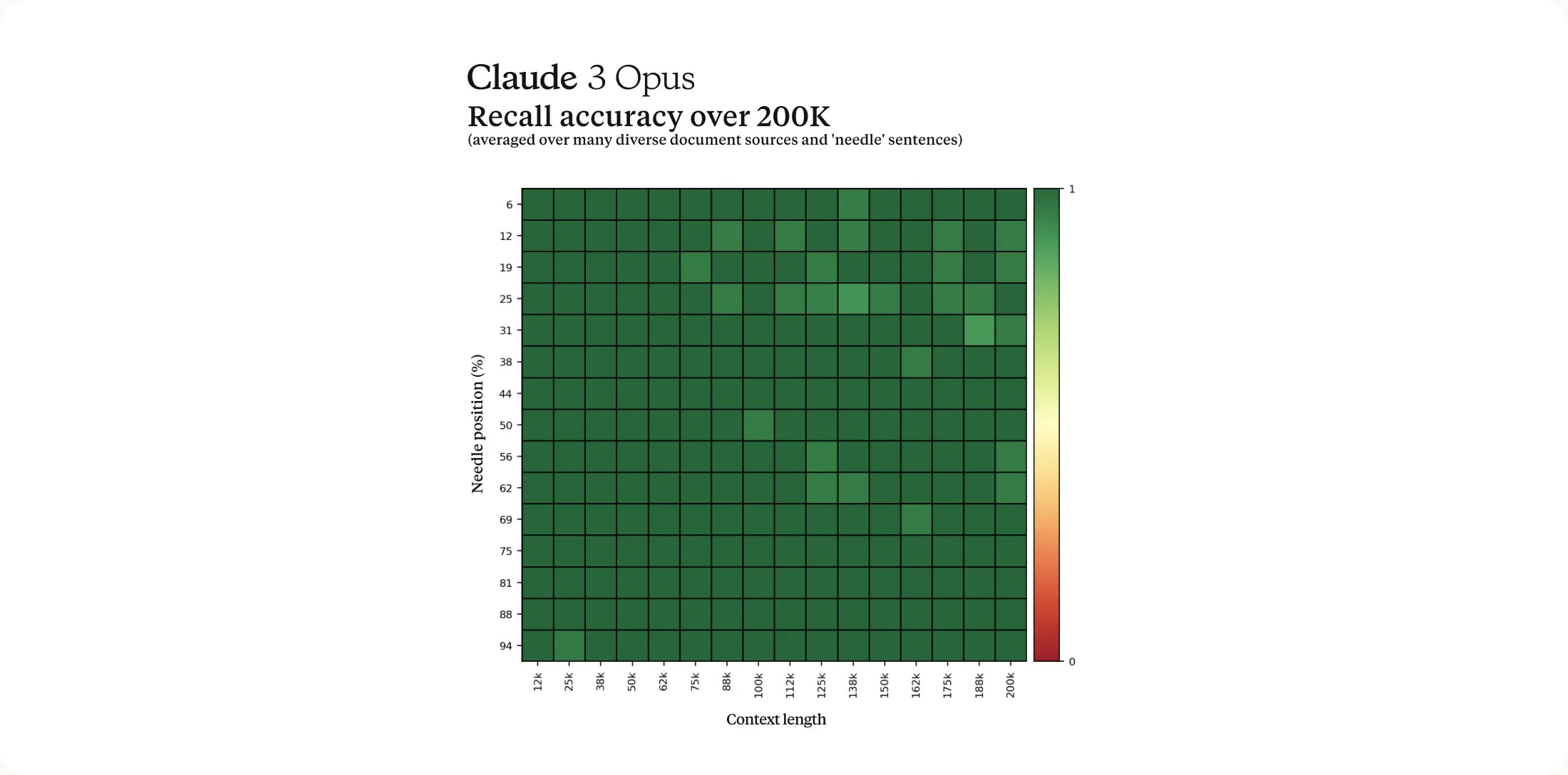
Can an AI language model become self-aware enough to realize when it's being evaluated? A fascinating anecdote from Anthropic's internal testing of their flagship Claude 3 Opus model (released today) suggests this may be possible - and if true, the implications would be wild.
Subscribe or follow me on Twitter for more content like this!
According to reports from Anthropic researcher Alex Albert, one of the key evaluation techniques they use is called "Needle in a Haystack." It's a contrived scenario designed to push the limits of a language model's contextual reasoning abilities. Here's how it works:
Keep reading with a 7-day free trial
Subscribe to AIModels.fyi to keep reading this post and get 7 days of free access to the full post archives.