
Can unified multimodal models align understanding and generation, without *any* captions?
Reconstruction alignment improves unified multimodal models

Unified multimodal models (UMMs) represent an ambitious goal in AI: creating single architectures that can both understand and generate visual content, much like how large language models have revolutionized text processing. These models aim to inherit the reasoning capabilities of language models while extending them to handle images.
However, UMMs face a fundamental limitation. Current training approaches rely on image-text pairs where captions provide supervision, but these captions are inherently sparse and miss critical visual details. Even captions spanning hundreds of words fail to capture essential elements like spatial layout, geometry, textures, and fine-grained attributes.

This creates a systematic bias. For instance, since captions rarely describe broccoli’s color, models overfit to the rule “broccoli → green,” often failing on prompts like “a yellow broccoli.” The model can recognize yellow broccoli when it sees one, but cannot generate it when asked — revealing a misalignment between understanding and generation capabilities.
Introducing Reconstruction Alignment (RecA)
The researchers introduce Reconstruction Alignment (RecA), a resource-efficient post-training method that addresses the sparse supervision problem through dense visual embeddings. Instead of relying on incomplete text descriptions, RecA leverages embeddings from visual understanding encoders like CLIP and SigLIP, which map pixels into a language-aligned semantic space.
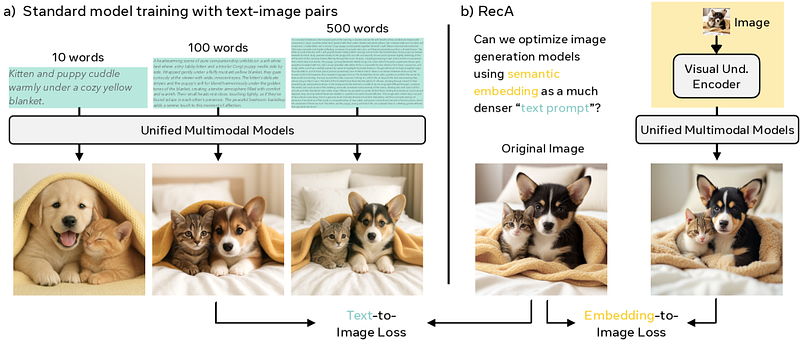
The key insight is that visual understanding encoders capture semantic structure far more effectively than generation encoders. These semantic embeddings provide dense, semantically grounded supervision without requiring paired captions, raising the central question: can we improve generation capabilities by training models with semantic embeddings as maximally informative “text prompts”?
Keep reading with a 7-day free trial
Subscribe to AIModels.fyi to keep reading this post and get 7 days of free access to the full post archives.