
Can text *finally* make robots dance exactly how we want them to?
HY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation

For years, generating realistic human motion from text descriptions has felt stuck. Current models either fail to understand what you’re asking for or produce movement that looks jerky and unnatural. Ask for an “angry walk toward a door,” and the model might generate walking that’s roughly the right speed but misses the emotional quality. Ask for something specific like “athletic jump with both arms extended,” and it often collapses entirely. The fundamental challenge is that motion has temporal structure, physical constraints, and an almost infinite solution space. Unlike generating a static image where pixels either look right or wrong, motion requires the model to understand not just the shape of movement, but how emotion deforms it, how intention curves trajectories, and how multiple text concepts combine into a single coherent sequence.
This is why every model released so far has struggled with instruction-following. They catch maybe 70% of what you asked for and miss the nuance. The problem isn’t that researchers don’t understand the algorithms well enough. The bottleneck is something deeper: models trained at small scale simply don’t develop the ability to understand and follow detailed instructions the way language models or image generators do.
The scaling hypothesis
The past five years of AI progress have been driven almost entirely by scaling. GPT-2 at 1.5 billion parameters could barely write coherent paragraphs. Increase that scale tenfold and something shifts. The model doesn’t just do the same thing slightly better but instead develops new capabilities. It reasons about edge cases it never encountered. It understands nuance and context in ways that feel qualitatively different from smaller versions.
The question for motion generation is straightforward: does this pattern hold? Or is something fundamentally different about this problem that makes scaling unhelpful?
HY-Motion answers that question by testing the hypothesis directly. Build a billion-parameter motion generation model and train it properly, and it develops instruction-following capabilities that smaller models never achieve. A small model learns to generate common motions competently. A billion-parameter model learns to listen to instructions, to combine concepts flexibly, to handle rare motion combinations and specific constraints. The research reveals that motion generation follows the same scaling laws as language and image generation, but only under one crucial condition: you need the right training data and the right training strategy.
Building the right foundation
Scaling only works if you have high-quality data to scale on. This is the unsexy part of the paper, the part many researchers skip, but it’s actually where much of the breakthrough lives.
The fundamental problem is that motion datasets are messy. Raw motion capture contains jitter and artifacts from the recording process. Text descriptions are often vague or incorrect. Without cleaning, any model trained on this noise learns garbled patterns. HY-Motion treats data as a first-class problem.
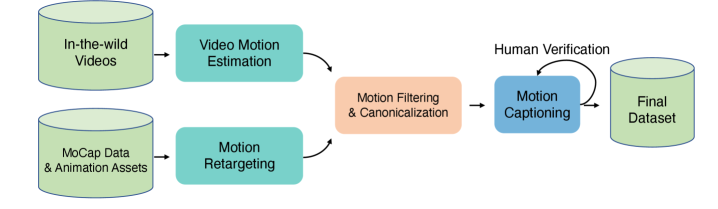
The processing pipeline performs rigorous motion cleaning to remove artifacts and temporal inconsistencies. Careful captioning ensures text actually describes the motion rather than being generic labels. The team then organized motions into a hierarchical structure that gives the model rich conceptual structure to learn from.
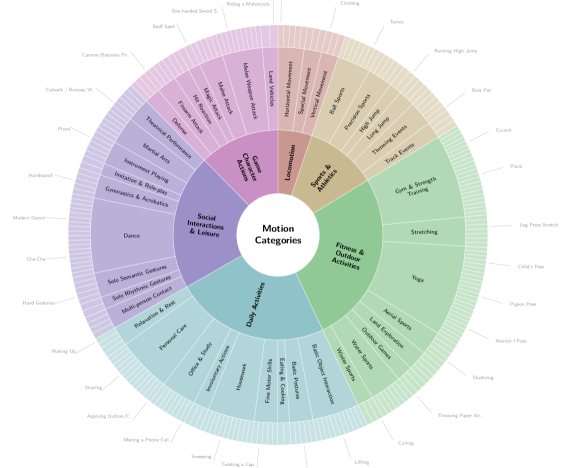
This hierarchical organization isn’t arbitrary. It reflects how motion actually structures itself in human understanding. The model learns not just individual motions, but relationships between them. How does walking differ from running? How does emotion modulate both? The cleaned dataset spans over 3,000 hours of motion data, and another 400 hours gets reserved for high-quality fine-tuning. This foundation is what makes scaling meaningful. Without it, you’d train a billion-parameter model on garbage.
