
Can image models understand what we’re asking for?
High-quality graphics vs high-quality understanding.

What questions do AI image models need to answer to be genuinely useful to humans? Until now, most discussions have focused on pure image quality - how realistic or artistic the outputs look. But Imagen 3, Google's latest image generation model (and a top trending paper on AImodels.fyi right now), suggests we should be asking a different and more fundamental question: can AI reliably understand and execute what humans are actually asking for?
I think this turns out to be a much harder question than it first appears. While we often judge these systems by image quality alone - how realistic or artistic their outputs look - this misses something fundamental: can they reliably turn our descriptions into the specific images we have in mind?
Speaking of real-world applications, I want to be upfront: this next section is an ad from our friends at Vizard.ai. But it highlights how AI can free you from tedious tasks.

Let AI be AI, and humans be human. Let AI handle tedious, heavy-lifting tasks, so humans can focus on creative and strategic work.
For Content Creators: AI easily turns existing long-form content into short clips ready for posting—maintain posting frequency and effortlessly drive more traffic from multiple social media pages.
For In-House Marketers/Social Media Professionals/Agencies: Seamlessly transform presentation or webinar videos into viral clips with trendy captions and headlines. Upload them to your company’s social pages with auto-generated descriptions and hashtags. Invite co-workers to collaborate in Vizard's workspace. You can also connect social media accounts to Vizard and post generated results directly.
For Small Business Owners: AI makes it easy to convert long videos into short, viral clips. No professional video editors are needed. This is especially useful for startup founders looking to post video content on social media.
Ok, now let’s check out how AI helps content creators, marketers, and small businesses get more done with less effort.
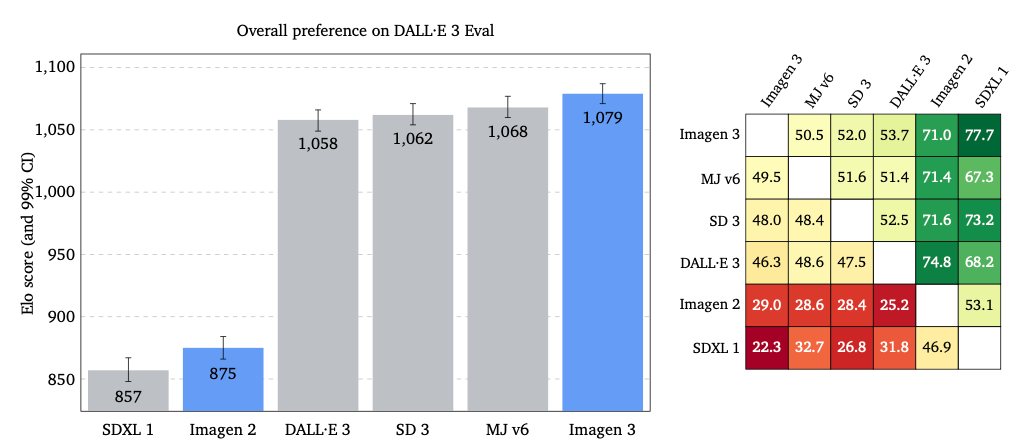
Imagen 3 helps us see why this question matters more than we might think. When researchers tested it against other leading models like DALL-E 3 and Midjourney, the results revealed a complex picture. While Imagen 3 showed notable improvements in prompt alignment (particularly on detailed prompts, with an average of 136 words), its advantages varied across different benchmarks - from huge leads on GenAI-Bench to smaller margins on DrawBench and close competition among leading models on DALL-E 3 Eval.
Consider what happens when you ask these systems to draw "a felt puppet diorama scene of a tranquil nature scene with a large friendly robot." Previous models might give you a robot, or a diorama, or a nature scene - but rarely all of these elements working together exactly as specified. The scene might look beautiful, but it wouldn't be quite what you asked for. Imagen 3 gets significantly closer to following such complex instructions precisely.

This matters because it points to a deeper truth about AI image generation. The real bottleneck isn't in producing stunning visuals - modern systems are remarkably good at that. The challenge is in bridging the gap between human intent and machine output. When we look at Imagen 3's results through this lens, we see evidence of genuine progress in solving this harder problem.
The results in the Imagen paper reveal an interesting pattern about what it means for an AI to truly understand our requests. When given simple prompts, most modern image generators perform similarly well. But as the requests become more complex and specific, we start to see meaningful differences that tell us about genuine understanding versus surface-level pattern matching.
Here’s two tidbits that suggest to me that Imagen 3 has a unique ability to understand the assignment:
When you write detailed descriptions, like the kind you might use to describe a complex scene to a person (130+ words), Imagen 3 achieves 72.9% alignment with the intended result, while other models manage only 57.9%. This dramatic difference suggests that longer, more detailed prompts aren't only harder for other models, but seem to pose a fundamentally different kind of challenge that tests true understanding.
This pattern becomes even clearer when we look at tasks requiring precise reasoning. In tests where models had to generate exact numbers of objects, Imagen 3 achieved 58.6% accuracy - a 12 percentage point lead over DALL-E 3. More revealing than the overall number is how the performance changed with complexity: when handling compound requests like "one cookie and five bottles," Imagen 3 maintained its accuracy while other models struggled significantly more.
I think it’s impressive that this improved understanding doesn't come at the cost of image quality. While Midjourney v6 still leads in pure aesthetic appeal, Imagen 3's results are nearly comparable while maintaining better fidelity to the original request. This suggests we're seeing a genuine advance in comprehension, not just a trade-off between beauty and accuracy.

I suspect the model's capabilities stem primarily from its multi-faceted training approach. Each image in the dataset was paired with both original captions (sourced from alt text and human descriptions) and synthetic captions generated using Gemini models with varied prompts. From what I can tell, this dual-caption strategy, combined with extensive filtering of AI-generated images and similar content, seems to create a training set that carefully balances diversity with precision.
But we shouldn't get carried away. Imagen 3 still fails at quantities over 40% of the time. It struggles with complex spatial relationships and action sequences (and I don’t think you’d want to use it for frame-by-frame video generation). Even its improved instruction-following isn't perfect - it's just better than what came before.
But again, what makes these limitations interesting is that they highlight where the real challenges lie. The problem isn't just technical realistic image generation - it's about understanding how humans communicate visual ideas. We're remarkably good at conveying complex visual concepts to each other through language, but getting machines to replicate this ability turns out to be far harder than making them generate attractive images.
Based on these results, I think we're getting a clearer picture of where image generation technology might need to go next. While photorealistic outputs and faster generation are important goals, I believe we need to focus more deeply on that core challenge of understanding human intent. Imagen 3's results suggest this kind of improvement is possible.
We may need to rethink how we evaluate progress in image generation. While output quality remains crucial, I think we should pay more attention to how well these systems understand and execute on human instructions. In my view, that's the metric that will likely determine how useful they become as creative tools, though reasonable people might prioritize different aspects depending on their needs.
This also raises interesting questions about what we mean by "understanding" in these systems. Imagen 3's improved performance doesn't necessarily mean it understands our requests the way a human would. But it does show we can make meaningful progress on getting AI to better align with human intent, even if we're not yet sure exactly how this understanding works.
The path forward will likely require advances on multiple fronts. We need better ways to communicate visual concepts to machines, improved architectures for maintaining precise constraints during image generation, and deeper insight into how humans translate mental images into words. Imagen 3 represents progress on some of these fronts.
What do you think? Let me know in the comments or in the Discord. I’d love to hear what you have to say.
"I suspect the model's capabilities stem primarily from its multi-faceted training approach. Each image in the dataset was paired with both original captions (sourced from alt text and human descriptions) and synthetic captions generated using Gemini models with varied prompts."
This was exactly the approach OpenAI followed when they first released DALL-E 3 - at the time, the only model that could reliably spell short words/phrases and was top-tier in prompt adherence and instruction following. I broke down that research paper in November 2023: https://www.whytryai.com/p/dall-e-3-better-captions-research-paper-summary
It's a testament to how quickly things change that DALL-E 3 now feels obsolete and outshined by so many other models like FLUX, Recraft, Ideogram, Imagen, etc. when it comes to prompt following.
And I agree:: Aesthetics seems a largely solved issue. Accurate and consistent instruction following is the next battleground.